

Sommario
- Il crawler di Google e il suo funzionamento
- Le notizie ufficiali di Google sul Crawl Budget
-
Domande e risposte sul Crawl Budget
- La velocità del mio sito influisce sul crawl budget?
- Gli errori influiscono sul crawl budget?
- La scansione è un fattore di ranking?
- URL canonici o embed influenzano il crawl budget?
- La direttiva Crawl-delay, nel file robots.txt viene interpretata da Googlebot?
- Il metatag nofollow influisce sul crawl budget?
- Analizzando i tempi/frequenza di scansione se vedo dei picchi mi devo preoccupare?
Dal motore di ricerca Google, dato l'innumerevole mole di articoli a tema ad opera di diversi Consulenti SEO, è stato pubblicato un articolo dedicato al significato di Crawl Budget in relazione all'operato di Googlebot, nelle due differenti versioni per desktop e mobile.
Andiamo ad analizzare il comunicato ufficiale, da prendere sempre con le pinze. Qua e la vado ad integrare il contenuto con informazioni utili a comprendere l'argomento.
Ricordate che questo argomento è molto importante in quanto è opportuno tenere sempre in considerazione la velocità di scansione e la frequenza dello spider di Google sulle vostre pagine.
La scansione è il primo passo per l'indicizzazione e senza non potrete mai vedere un vostro risultato sulla SERP del motore di ricerca o modificarne la posizione a seguito di aggiornamento delle informazioni.
Cosa è, come funziona e come ottimizzare il crawl budget di un sito web Share on X
Il crawler di Google e il suo funzionamento
Prima di comprendere come Google investe le proprie energie è necessario capire nel dettaglio il funzionamento dello spider del motore di ricerca e cosa intendiamo per Crawl Budget.
Cos'è Googlebot
Per scansionare i siti web presenti in rete il motore di ricerca Google utilizza dei bot, ossia dei robot software, che in maniera automatica leggono il contenuto di una pagina web e saltano al contenuto successivo mediante i link in essa contenuti.
In alcuni casi (e senza nessuna garanzia temporale o di effettiva scansione) Googlebot passa a scansionare direttamente un url quando da Search Console:
- inseriamo un nuovo sito web nella console (una volta loggati in Search Console > Aggiungi Proprietà);
- gli viene sottoposta una nuova sitemap XML (da Search Console, selezione proprietà > scansione > Sitemap);
- chiediamo al motore di ricerca di recuperare un determinato URL (da Search Console, selezione proprietà > scansione > Visualizza come Google);
Lo spider di Google, a meno che non abbiamo specificato diversamente nel file robots.txt (e se il file robots.txt non presenta errori) effettuerà la scansione delle pagine di tutto il sito (con i suoi tempi) seguendo gli URL presenti a partire dalla pagina iniziale (ossia la pagina a cui punta il dominio nudo e crudo, configurata mediante le impostazioni del server Web). Lo spider quando troverà dei metatag robots potrebbe (non è detto che lo faccia effettivamente eh!):
- non inserire il contenuto nell'indice (se l'attributo è noindex);
- non seguire i link presenti nella pagina (con attributo nofollow);
Una volta scansionata la pagina, se non sono presenti errori, lo spider di Google la inserirà nel suo indice correlandola con diverse query.
Negli ultimi 10 anni lo spider di Google si è prima sdoppiato (o sduplicato cit gli anni 2000 e le cassette audio) scansionando il sito con due diverse versioni del bot, che differivano nello user-agent con cui veniva letto il contenuto:
- il classico GoogleBot per recuperare i contenuti in modalità desktop;
- uno con user-agent mobile, per visualizzare i contenuti simulando di essere uno smartphone, modificato l'ultima volta il 18 aprile 2016;
Poi, complice il passaggio alla fruizione di internet da parte dell'utenza nella quasi totalità con dispositivo mobile, alla scansione dei siti SOLO con crawler con user agent-mobile.
Il motivo è molto semplice e va ricercato nella renderizzazione dei siti web in funzione della chiamata che viene effettuata. Collegandosi ad un sito web infatti esso viene mostrato all'utenza in funzione di come viene fatta la chiamata, se richiedendo un sito ottimizzato per la visualizzazione su mobile o su desktop.
Cos'è il Crawl Budget
Lo spider di Google per poter saltare da un link all'altro, scansionare il contenuto e renderizzarlo investe del tempo e delle energie (oltre all'investimento iniziale degli ingegneri di Google nel realizzare questo software) che moltiplicato per il numero di pagine presenti in ogni sito web del mondo (secondo internetlivestats.com ad oggi sono oltre 1 miliardo e cento milioni) richiede un considerevole costo in termini monetari.
Per questo motivo ogni SEO analizza il "Budget del Crawl (GoogleBot) del motore di ricerca" assegnato al proprio sito web, per comprendere se il progetto seguito richiede troppe o poche risorse al motore di ricerca. Pur se come nell'articolo da Google ci spiegano che non è importante avere poche risorse allocate, in realtà è un problema, in quanto il sito vedrà le proprie pagine indicizzate con tempi molto dilatati, mentre troppe risorse allocate per un periodo di tempo elevato (senza giustificato motivo) potrebbero portare ad una penalizzazione a causa dello "spreco" di energie che andiamo a richiedere al motore di ricerca.
Il Crawl Budget DEVE variare da sito a sito, in funzione delle dimensioni del progetto e dell'aggiornamento contenutistico e tecnico.
Per comprendere frequenza e velocità con cui lo spider di Google passa sul vostro sito dovete aprire la Search Console e, una volta selezionata la vostra proprietà, selezionare Scansione > Statistiche di scansione.
Nella pagina che si aprirà nella GSC potrete così trovare tre grafici, relativi agli ultimi 90 giorni del sito in esame, in cui potrete analizzare:
- pagine sottoposte a scansione giornaliera;
- quanti Kilobyte Googlebot scarica quotidianamente;
- quanto tempo impiega (in millisecondi) a scaricare una pagina del sito;
Per ognuno di questi grafici a fianco avrete il valore più alto, medio e basso degli ultimi tre mesi.
 Come vedremo a seguire, secondo le fonti ufficiali di Google, il Crawl Budget assegnato al nostro sito viene definito come "il numero di URL che Googlebot può e vuole scansionare"; Il "potere e il volere" vengono definiti dal limite alla velocita di scansione e dalle esigenze del crawl (che analizziamo nei paragrafi a seguire).
Come vedremo a seguire, secondo le fonti ufficiali di Google, il Crawl Budget assegnato al nostro sito viene definito come "il numero di URL che Googlebot può e vuole scansionare"; Il "potere e il volere" vengono definiti dal limite alla velocita di scansione e dalle esigenze del crawl (che analizziamo nei paragrafi a seguire).
Le notizie ufficiali di Google sul Crawl Budget
Nell'introduzione dell'articolo da Google ci fanno sapere che per la maggior parte dei webmaster e dei SEO non si deve preoccupare di analizzare il crawl budget allocato al proprio progetto, in quanto se il sito ha meno di un migliaio di URL le risorse saranno allocate in maniera ottimizzata.
Quando il sito al contrario ha dimensioni considerevoli in quel caso è opportuno esaminare e allocare le risorse in maniera ottimizzata, in particolare quando vengono generate molte pagine in base ai parametri URL (che magari hanno lo stesso contenuto, ma per Google sono effettivamente pagine distinte).
Esempio: www.esempio.it/guida-crawl-budget.html è un URL che contiene tutte le guide sul "Crawl Budget", www.esempio.it/guida-crawl-budget.html?orderByDate=ASC per il motore di ricerca è un altro URL con tutte le guide ordinate in funzione della data di pubblicazione. Il contenuto però a conti fatti è identico e al Crawl abbiamo fatto sprecare risorse.
Il limite alla velocità di scansione
Googlebot è a tutti gli effetti un visitatore di un sito web e per questo richiede risorse al server che ospita il dominio per renderizzare le pagine. Una elevata scansione potrebbe inficiare le performance del server e per questo da Google hanno limitato il tasso di recupero delle risorse, per un determinato sito, ad un ben distinto massimale.
In sostanza Googlebot effettuerà un determinato numero di connessioni simultanee in parallelo ad un sito web in definiti intervalli di tempo.
Questa velocità di scansione può variare nel tempo a seconda delle:
- performance di scansione (crawl healt): se il sito risponde velocemente aumenta la frequenza della scansione, se il sito (e quindi l'host su cui risiede) fatica a rispondere Googlebot "striscierà" di meno tra i nostri contenuti;
- impostazioni in Search Console: possiamo ridurre/aumentare la scansione di un nostro sito, ad opera di GoogleBot, direttamente da Search Console. Per farlo selezioniamo una proprietà controllata in Search Console, facciamo click sull'icona dell'ingranaggio in alto a destra e selezioniamo impostazioni sito, nella pagina che compare sotto alla voce Velocità di scansione selezioniamo limita la velocità massima di scansione di Google abbassando o aumentando la frequenza. Aumentare tale valore, ci fanno sapere dal motore di ricerca, non garantisce che effettivamente aumenterà la frequenza;
La esigenze (richieste) del crawl
Al fine di scansionare correttamente un sito web il crawler di Google ha delle determinate esigenze tecniche, che se non rispettate inficiano il corretto passaggio del bot.
Nel dettaglio se non vi è una richiesta di indicizzazione Googlebot effettuerà meno passaggi. Dal motore di ricerca di Mountain View ci fanno sapere che sono due i fattori che influenzano particolarmente il passaggio del bot (che quindi soddisfano le sue richieste al fine di autorizzare una scansione o una modifica alla frequenza dei passaggi):
- popolarità: gli URL più "popolari" (ossia con CTR più alto quando cliccati da SERP di Google) verranno scansionati più frequentemente, in cerca di eventuali modifiche al contenuto;
- aggiornamento dei contenuti (quanto è "fresco" un contenuto):
Da quello che viene scritto sul blog ufficiale per i Webmaster di Google possiamo quindi dire che un sito con una frequenza di scansione più elevata, da parte di Googlebot (e giustificata dalla mole dei contenuti presenti al suo interno), è un sito reputato più interessante dal motore di ricerca e per questo da tenere sotto occhio per eventuali modifiche.
In aggiunta ci viene spiegato che, se modifichiamo gli URL del nostro sito, sicuramente Googlebot incominciera ad aumentare i suoi sforzi per reindicizzare (o modificare l'indicizzazione pre esistente) le diverse pagine.
Passaggio da noindex a index dei tag, con conseguente aumento della frequenza di scansione
Quali fattori influenzano il Crawl Budget
Secondo le parole di Google avere degli URL di "basso valore" può influenzare negativamente la scansione e la relativa indicizzazione da parte del Crawler. Per cui se fate perdere tempo a Googlebot nella scansione di contenuti di "scarsa qualità" potrete vedere penalizzata la visibilità del vostro sito sul motore di ricerca, questo perché vanificare le risorse del server di Google dedicato alla scansione della rete potrebbe bloccarlo o generare un significativo ritardo dalla scoperta di contenuto con più valore sullo stesso sito o su altri.
Sempre secondo le analisi effettuate dai tecnici di Mountain View alcuni dei fattori che identificano un URL come "non buono" sono:
- contenuti duplicati sul sito;
- pagine con errori non gravi;
- pagine compromesse da terzi o hackerate (ossia che, a causa di una falla di sicurezza, hanno avuto una iniezione di contenuto da parte di terzi esterni al sito);
- contenuti di bassa qualità o spam;
- pagine infinite o "entry page", che richiedono un click suppletivo per far visualizzare il contenuto;
Domande e risposte sul Crawl Budget
Nell'articolo dedicato al crawl budget possiamo vedere diverse domande sull'argomento. Ne aggiungo una (con relativa risposta) che alcuni utenti di questo sito mi hanno fatto nei tempi passati.
La velocità del mio sito influisce sul crawl budget?
Si, la velocità di caricamento di un sito influisce sul crawl budget. Un host/server performante migliora l'esperienza utente e nel contempo permette a Googlebot di scansionare più velocemente il materiale presente sul sito.
Gli errori influiscono sul crawl budget?
Si, un numero elevato di errori 5xx o il timeout della connessione fanno perdere tempo al crawler, abbassando la frequenza della scansione. Per questo è sempre opportuno analizzare gli errori di scansione in Search Console e cercare di risolverli quando si presentano.
La scansione è un fattore di ranking?
Dipende, aumentare la velocità di scansione non influisce direttamente sul ranking di un risultato (in quanto Google analizza centinaia di segnali diversi), ma un URL per essere posizionato è necessario prima essere indicizzato.
URL canonici o embed influenzano il crawl budget?
Si, tutti gli URL come AMP o contenuti tradotti (hreflang) vengono scansionati e per questo influiscono sul crawl budget e lo stesso si può dire di JS o CSS incorporati mediante collegamento file. Dei redirect da file a file consequenziali possono quindi influenzare negativamente il crawl budget.
La direttiva Crawl-delay, nel file robots.txt viene interpretata da Googlebot?
All'interno del file robots.txt possiamo impostare l'intervallo temporale ogni quanto effettuare la scansione del nostro sito, in maniera tale da non sovraccaricare il server. Googlebot però non interpreta questa informazione, per cui è superflo inserirla a tale scopo. Per provare a indicare allo spider del motore di ricerca la frequenza di scansione è opportuno intervenire mediante Search Console (vedi paragrafo limite della velocità di scansione).
Il metatag nofollow influisce sul crawl budget?
Dipende. Se un URL ha all'interno la direttiva nofollow Googlebot non lo seguirà, ma lo spider potrebbe seguire un percorso differente (senza direttiva nofollow) per arrivare a scansionare la risorsa.
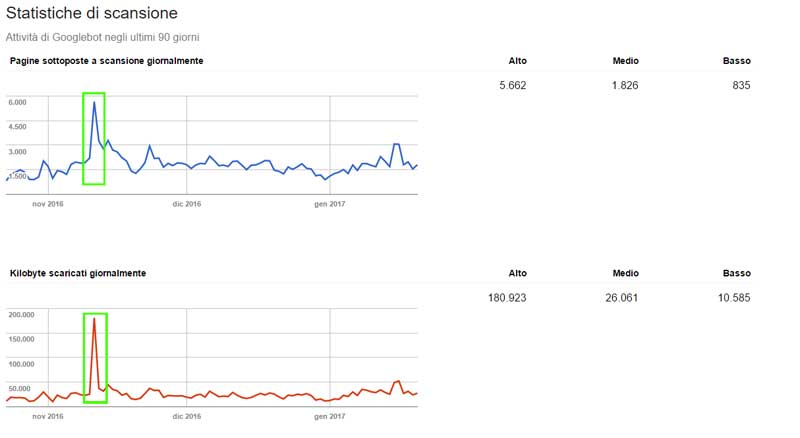
Analizzando i tempi/frequenza di scansione se vedo dei picchi mi devo preoccupare?

Analisi delle statistiche di scansione a seguito di cambio di layout di un sito, con conseguente aumento degli URL complessivi
Dipende. Un picco estemporaneo può essere giustificato da una modifica massiva alle pagine che compongono il sito web come lo è una crescita costante nel tempo a seguito di modifiche quotidiane ai contenuti. Una crescita della frequenza di scansione media, senza un effettivo intervento da parte degli amministratori del sito richiede una analisi per comprenderne le cause e, nel caso, ricercare una soluzione.